timeseriesflattener#

timeseriesflattener is a Python package for generating features time series data to be used as predictors in machine learning models. The package implements a number of methods for aggregating time series data into features.
Functionality#
timeseriesflattener includes features required for converting any number of (irregular) time series into a single dataframe with a row for each desired prediction time and columns for each constructed feature. Raw values are aggregated by an ID column, which allows for e.g. aggregating values for each patient independently.
When constructing feature sets from time series in general, or medical time series in particular, there are several choices one needs to make.
When to issue predictions (prediction time). E.g. at every physical visit, every morning, or another clinically meaningful time.
How far back/ahead from the prediction times to look for raw values (lookbehind/lookahead).
Which method to use for aggregation if multiple values exist in the lookbehind.
Which value to use if there are no data points in the lookbehind.
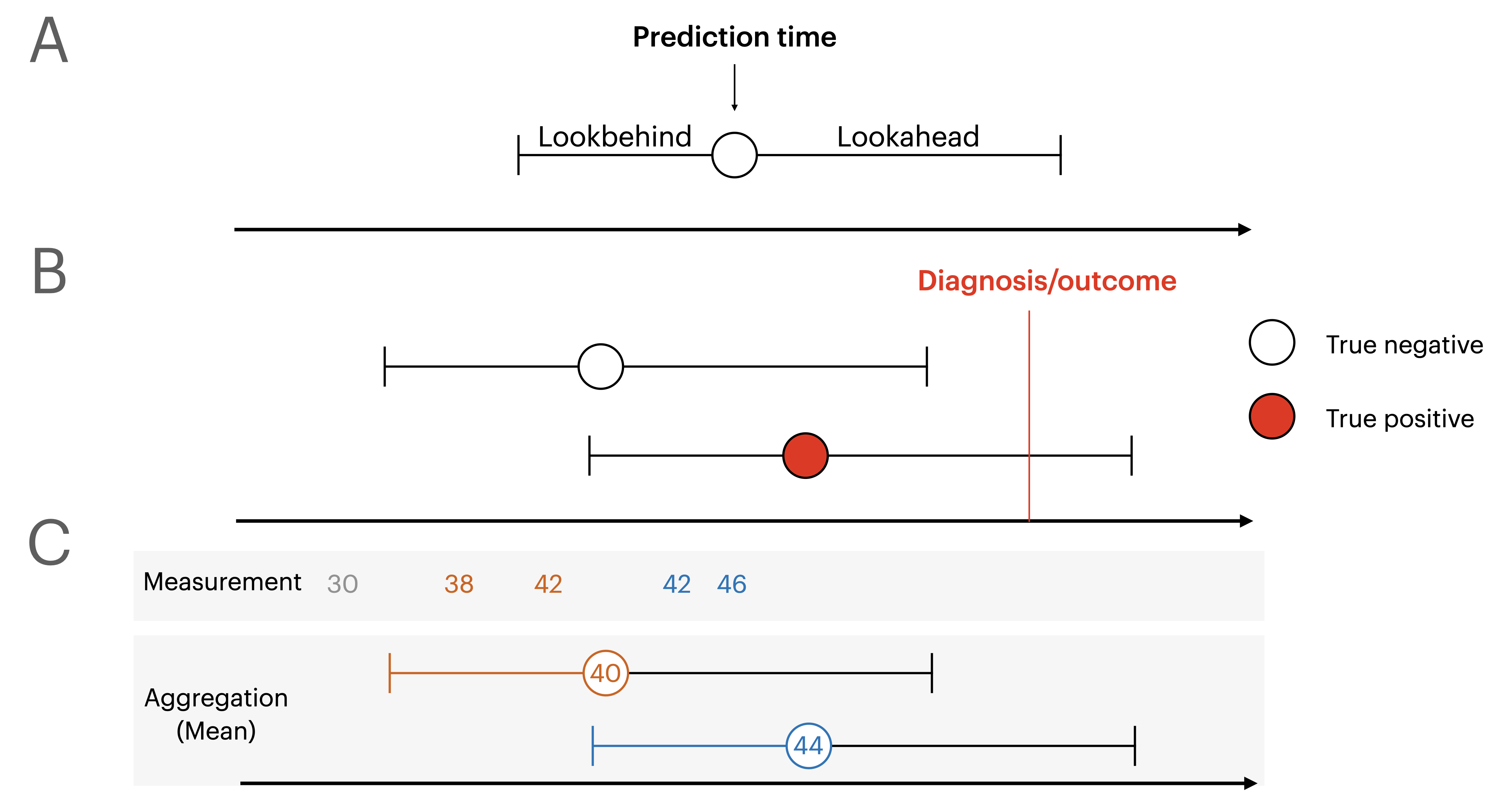
The above figure graphically represents the terminology used in the package.
A) Lookbehind determines how far back in time to look for values for predictors, whereas lookahead determines how far into the future to look for outcome values. A prediction time indicates at which point the model issues a prediction, and is used as a reference for the lookbehind and lookahead.
B) Labels for prediction times are true negatives if the outcome never occurs, or if the outcome happens outside the lookahead window. Labels are only true positives if the outcome occurs inside the lookahead window.
C) Values within the lookbehind window are aggregated using a specified function, for example the mean as shown in this example, or max/min etc.
Multiple lookbehind windows and aggregation functions can be specified for each feature to obtain a rich representation of the data. See the tutorials for example use cases.
Where to ask questions?#
To ask report issues or request features, please use the GitHub Issue Tracker. Otherwise, please use the discussion forums.
Type |
|
Bug Reports |
|
Feature Requests & Ideas |
|
Usage Questions |
|
General Discussion |